java基础二
面向对象基础
面向对象和面向过程的区别
面向过程编程(Procedural-Oriented Programming,POP)和面向对象编程(Object-Oriented Programming,OOP)是两种常见的编程范式。
- 面向过程(POP):是一种以过程为中心的编程思想,主要关注问题解决的步骤和流程。它将问题分解成一系列详细的步骤,然后通过函数实现这些步骤,并依次调用这些函数来解决问题。
- 面向对象(OOP):是一类以对象作为基本程序结构单位的编程范式。它强调以对象为核心,通过创建和使用对象来模拟现实世界中的实体和它们之间的关系。面向对象编程关注问题的本质和对象之间的交互。
相比较于 POP,OOP 开发的程序一般具有下面这些优点:
- 易维护:由于良好的结构和封装性,OOP 程序通常更容易维护。
- 易复用:通过继承和多态,OOP 设计使得代码更具复用性,方便扩展功能。
- 易扩展:模块化设计使得系统扩展变得更加容易和灵活。
创建一个对象用什么运算符
在 Java 中,创建对象使用 new 运算符。new 运算符首先在堆内存中为对象实例分配空间。 然后new 运算符会调用相应类的构造函数,来初始化对象的状态,最后new 运算符返回堆内存中对象的引用(即内存地址)。这个引用在栈内存中 ,指向创建的对象,使得程序可以通过这个引用访问该对象的数据和行为。
对象实体与对象引用有何不同
- 对象实体是通过
new运算符创建的实际对象,它存储了对象的属性(字段)和行为(方法)。 - 对象引用是一个变量,它储存了指向堆内存中对象实体的地址。是一个引用类型变量,并不直接存储对象的实际数据,而是存储了对象在堆内存中的地址。通过对象引用,程序可以访问和操作该对象的状态。
- 对象实体位于堆内存中 , 而对象引用存储在栈内存中。
- 对象实体的生命周期由垃圾回收器管理。当没有任何引用指向该对象时,它会被垃圾回收器回收。
- 对象引用的生命周期与栈中的方法调用相关,当方法调用结束时,栈中的局部变量(包括对象引用)会被销毁。
- 一个对象引用可以指向0个或一个对象实体 ,一个对象实体可以有多个对象引用指向它。
对象的相等和引用相等的区别
- 对象相等是指两个不同的对象是否具有相同的内容,也就是它们的属性值是否相等。
- 引用相等是指两个对象引用是否指向同一个内存地址,也就是它们是否指向同一个对象实例。
构造方法有哪些特点?
- 构造方法(Constructor)是类中的一种特殊方法,用于在创建对象时初始化对象的状态。
- 构造方法的名称必须与类名完全相同,且没有返回类型,不能使用void声明。
- 且构造方法可以被重载。因此,一个类中可以有多个构造方法,这些构造方法具有不同的参数列表,以提供不同的对象初始化方式。
构造方法是否可被 override?
- 构造方法不能被重写(override)。
- 在Java中,子类可以继承父类的属性和方法。但是,由于构造方法不是类的成员,因此它们不会被子类继承,也就不存在被重写的问题。
- 另外方法重写(override)针对的方法签名是一样的,而父类和子类的构造器都必须以类名命,因此不符合方法重写的定义。
- 当子类创建一个实例时,它总是首先调用父类的构造方法 ,如果子类重写了父类的构造方法, 可能会导致父类的初始化逻辑无法执行,从而破坏对象的完整性和一致性。
面向对象特性
封装
概念
封装是面向对象的基本特性之一,它指的是将对象的属性(数据)和行为(方法)绑定在一起,并隐藏对象的内部细节,仅对外暴露必要的接口以进行访问和修改。
实现方式
通过访问控制修饰符(如 private、protected、public)来控制属性和方法的可见性。 常见的做法是将类的成员变量设为 private,而提供公共的 getter 和 setter 方法进行访问。
好处
- 提高了安全性,防止外部代码直接访问和修改对象的内部状态。
- 提高了灵活性,可以在不改变外部接口的情况下,修改对象的内部实现。
继承
概念
继承是面向对象的另一个基本特性 ,它允许一个类继承另一个类的属性和方法。子类可以重用父类的代码,同时也可以添加或覆盖父类的方法,实现代码复用和扩展。
实现
在 Java 中,子类通过 extends 关键字继承父类的属性和方法。子类可以继承父类的所有公共和保护成员(字段和方法),并且可以重写父类的方法来实现不同的行为。
好处
- 提高代码复用性,通过继承,子类可以重用父类的代码,减少代码冗余。
- 易于维护:当父类的代码需要修改时,只需要修改一个地方,所有继承该父类的子类都会自动更新。
注意!
- 子类拥有父类对象所有的属性和方法,但是父类中的私有属性和方法子类是无法访问,只是拥有。
- Java 是单继承的,即每个类只能有一个直接父类。
多态
概念
多态指的是在面向对象编程中, 同一个方法可以执行不同的行为。具体来说,多态允许通过父类引用指向子类对象,从而在运行时根据对象的实际类型来决定调用哪个方法。
实现
多态可以通过编译时多态(静态多态)和运行时多态(动态多态)实现。
- 编译时多态(静态多态):
- 主要通过方法重载(Method Overloading)来实现。
- 方法重载是指在同一个类中,允许存在一个以上的同名方法,只要它们的参数列表不同即可。
- 编译器在编译时就能够根据方法调用传入的参数类型来确定调用哪个方法。
- 运行时多态(动态多态):
- 主要通过方法重写(Method Overriding)和接口实现来实现的。
- 当使用父类类型的引用来指向子类对象时,JVM会在运行时根据对象的实际类型来确定应该调用哪个方法。
- 当使用接口类型的引用来指向一个实现了该接口的对象时,同样JVM会在运行时根据对象的实际类型来确定应该调用哪个具体的实现。
好处
- 提高了代码的灵活性和可扩展性,当需要添加新的功能时,只需要添加新的类并实现相应的接口或继承相应的父类即可,而无需修改现有的代码。
接口和抽象类的共同点
- 实例化:接口和抽象类都不能直接实例化,只能被实现(接口)或被继承(抽象类)后才能创建具体的对象。
- 抽象方法:接口和抽象类都可以包含抽象方法。抽象方法没有方法体,必须在子类或实现类中实现。
- 具体方法: 从 Java 8 开始,接口可以有默认方法(
default方法),这些方法可以有具体实现,而抽象类始终可以有具体方法。
接口和抽象类的区别
- 设计目的:接口主要用于对类的行为进行约束,而不关心这些行为的具体实现。 抽象类用于对一些共有特征或行为的抽象,其中为子类提供了共享的属性和方法。它是对类的抽象,提供了子类可以继承的公共行为。
- 继承和实现:一个类可以实现多个接口,但只能继承一个抽象类。
- 成员变量:接口中的成员变量默认是
public static final类型的,不能被修改且必须有初始值。抽象类的成员变量可以有任何修饰符,可以在子类中被重新定义或赋值。 - 方法:Java 8 之前,接口中的方法默认是
public abstract,也就是只能有方法声明。自 Java 8 起,可以在接口中定义default(默认) 方法和static(静态)方法,可以有具体实现。 自 Java 9 起,接口可以包含private方法。而抽象类中的方法可以有具体的实现,也可以有抽象方法(没有具体实现的方法)。
Java 8 引入的
default方法用于提供接口方法的默认实现,可以在实现类中被覆盖。这样就可以在不修改实现类的情况下向现有接口添加新功能,从而增强接口的扩展性和向后兼容性。Java 8 引入的
static方法无法在实现类中被覆盖,只能通过接口名直接调用(MyInterface.staticMethod()),类似于类中的静态方法。static方法通常用于定义一些通用的、与接口相关的工具方法,一般很少用。Java 9 允许在接口中使用
private方法。private方法可以用于在接口内部共享代码,不对外暴露。
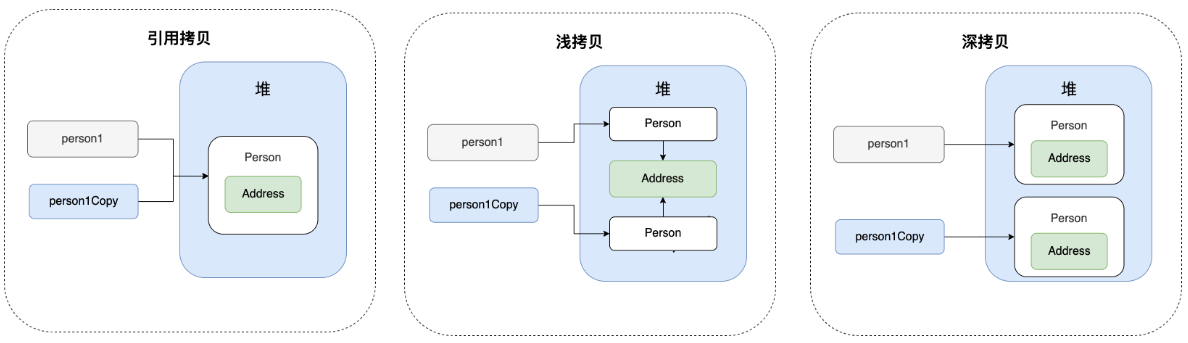
拷贝
浅拷贝
浅拷贝是指在复制对象时,在堆上创建一个新的对象,如果原对象包含基本数据类型字段,这些字段会被值拷贝;如果包含引用类型字段(如对象、数组等),这些字段会被引用拷贝,也就是说,对于引用类型的成员,实际上复制的是引用,而不是引用所指向的对象。即新对象和原对象的引用类型字段会指向同一个内存地址。
特征:
- 基本数据类型字段会被复制,即深度复制它们的值。
- 引用类型字段会复制引用,指向原始对象中的同一实例。
深拷贝
创建一个新对象,不仅复制基本数据类型成员的值,对于引用数据类型的成员及这些成员所引用的其他对象,都会递归地会为其创建新的对象,并复制其内容,使得新对象和原始对象完全独立,修改其中一个对象的引用类型成员不会影响到另一个对象。
特征:
- 基本数据类型字段会被复制。
- 引用类型字段会被递归复制,即每个引用类型字段都会新建一个对象。
引用拷贝
将一个对象的引用直接赋值给另一个变量,这两个引用类型的变量指向同一个对象。这样在修改其中一个变量指向的对象时,另一个变量也会随之改变。实际上引用拷贝并不是真正意义上的拷贝,而是共享同一份数据。
特征:引用拷贝并不会复制对象的内容,而是直接复制对象的内存地址。结果是,源对象和目标对象指向同一个对象,它们的内容会随着任意一个对象的变化而变化。
深拷贝和浅拷贝的区别
- 浅拷贝复制对象时,对于字段中的引用类型(如对象、数组等),只会复制其引用,而不会递归地创建新的对象。这意味着源对象和目标对象共享对引用类型字段的引用。
- 深拷贝复制对象时,会为每个引用类型字段递归地创建一个新的对象,因此源对象和目标对象完全独立,修改一个对象不会影响另一个对象。
怎样实现浅拷贝和深拷贝
浅拷贝实现
在Java中,要实现浅拷贝,可以让类实现Cloneable接口,并重写clone()方法。Object类中的clone()方法是受保护的,因此需要在子类中暴露它(通常是通过public方法)。浅拷贝的实现相对简单,因为它只需要调用超类的`clone()方法(即super.clone()),这会复制当前对象并返回一个新的实例,但只复制基本数据类型和引用类型的引用,而不复制引用的对象本身。
深拷贝实现
要实现深拷贝,除了让类实现Cloneable接口并重写clone()方法外,还需要在clone()方法内部对所有的引用类型属性进行递归的克隆。这意味着每个引用类型属性所指向的对象也必须实现Cloneable接口,并且有自己的clone()方法实现。在重写clone()方法时,需要手动调用这些引用类型属性的clone()方法,以确保它们也被深拷贝。
Object
Object 类的常见方法有哪些?
Object 类是一个特殊的类,是所有类的父类,主要提供了以下 11 个方法:
1 | |
== 和 equals() 的区别
==是操作符
- 对于基本数据类型来说,
==比较的是值。 - 对于引用数据类型来说,
==比较的是两个引用是否指向同一个对象(即它们所储存的内存地址是否相同)。
equals() 是 Object 类的方法,所有类都继承了这个方法。它用于比较两个对象是否相同。具体的实现依赖于类是否重写了 equals() 方法。
如果类没有重写 equals() 方法,它会继承 Object 类中的equals()方法。默认情况下,等价于通过“==”比较这两个对象。
如果类重写了 equals()方法,可以比较两个对象中的内容是否相等;若它们的内容相等,则返回 true。
hashCode的作用
**hashCode()** 返回一个整数,用来表示对象的哈希值。
hashCode可以优化查找效率,集合类(如 HashMap、HashSet)通常通过哈希表(hash table)来存储元素。哈希表使用 哈希值 来决定对象存储的位置,从而可以在常数时间内(O(1))找到对象。
且通过 hashCode(),集合类可以首先使用哈希值进行初步的快速查找。如果两个对象的哈希值不同,集合类就可以立即确定它们不相等,从而避免了调用 equals() 进行更昂贵的比较。
两个对象的 hashCode()相同,则 equals()是否也一定为 true吗?
两个对象的hashCode 值相等并不代表两个对象就相等,因为 hashCode() 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关。
为什么重写 equals() 时必须重写 hashCode() 方法?
如果重写了equals()方法但没有重写hashCode()方法,就可能导致两个内容相等的对象(即equals()方法返回true)可能会有不同的hashCode()值。
这会使得在使用基于哈希的集合时,这些对象被视为不同的元素,从而导致集合中出现重复元素的问题。
String
String、StringBuffer、StringBuilder 的区别?
可变性
- String是不可变的,一旦创建后其内容无法更改。每次修改 String 时,都会创建一个新的对象。
StringBuilder与StringBuffer都继承自AbstractStringBuilder类,AbstractStringBuilder定义了一些字符串的基本操作,如append、insert 等方法,因此StringBuffer和StringBuilder 允许对字符串进行修改而不会创建新的对象。
线程安全性
- 由于String是不可变的,因此它是线程安全的。多个线程可以安全地共享同一个String对象。
- StringBuffer也是线程安全的,因为它的所有方法都被
synchronized关键字修饰。 - 而StringBuilder不是线程安全的,它的方法没有被
synchronized修饰,因此在多线程环境中使用可能会导致数据不一致的问题。
性能
- Str****ing:由于String的不可变性,每次对String的修改都会创建新的对象,这会导致大量的内存分配和垃圾回收,从而影响性能。
- StringBuffer:由于StringBuffer是线程安全的,它的性能在多线程环境中是可靠的,但在单线程环境中,由于synchronized关键字的开销,它的性能可能略低于StringBuilder。
- StringBuilder:StringBuilder在单线程环境中提供了更高的性能。由于没有线程安全的开销,它可以更快地执行字符串修改操作。
总结:
String:不可变,线程安全,适合常量和少量修改。StringBuffer:可变,线程安全,适合多线程修改。StringBuilder:可变,非线程安全,适合单线程修改。
String 为什么是不可变的?
- String类被final修饰,意味着String不能被继承,防止子类重写其方法。
- String 中存储字符串数据的字段 value是一个字符数组 ,被声明为 final 和 private,意味着value数组在初始化后不能被修改指向其他数组。
- 且String类没有提供任何可以修改自身内容的方法
- String 不可变的设计使得 Java 可以在字符串常量池中安全地共享和复用字符串,提高内存使用效率。
- 多个线程可以安全地共享一个 String 实例,因为它的值不能被改变。这减少了同步的开销,避免了多线程环境下的数据竞争和不一致性。
字符串拼接用“+” 还是 StringBuilder?
字符串对象通过+拼接,实际上是通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个 String 对象 。
对于少量的字符串拼接,用+ 更为简洁和易读。
但对于大量的字符串拼接操作,尤其是在循环中,直接使用 + 运算符可能会导致性能问题,因为它每次都会创建一个新的 String 对象。这会增加内存消耗 。
而StringBuilder 是一个可变的字符序列,它提供了用于字符串拼接的 append 方法。与 String 不同,StringBuilder 不会每次拼接都创建新的对象,而是在内部维护一个可变的字符数组,并随着拼接操作的进行而动态地调整其大小。
因此,当需要执行大量的字符串拼接操作时,使用 StringBuilder 通常会比使用 + 运算符更高效,因为它避免了频繁的对象创建和内存分配。
字符串常量池了解吗?
概念
字符串常量池是一个存储字符串字面量的特殊内存区域。相同内容的字符串只会在池中存储一份,从而节省内存并提高性能。
作用
当你在代码中创建一个常量字符串时,JVM 首先会先检查该字符串是否已经存在于常量池中。如果存在,就直接返回池中的引用,而不是重新创建一个新的 String 对象。 这样可以使得多个相同内容的字符串共享同一个实例,避免了重复的对象创建,从而减少了内存分配和垃圾回收的压力。
字符串对象的创建过程
字面量字符串:当你在 Java 代码中使用字符串字面量(如 "hello")时,JVM会首先在字符串常量池中查找是否存在字面量”hello”。如果存在,则直接返回该字面量对应的字符串对象的引用;如果不存在,则创建一个新的字符串对象并将其添加到字符串常量池中,然后返回该对象的引用。
通过 new 创建字符串:当你使用 new String("hello") 创建一个字符串时,无论字符串常量池中是否已经存在字面量”hello”,JVM都会在堆内存中创建一个新的字符串对象。然后,它会检查字符串常量池中是否存在该字面量,并将新创建的字符串对象的内部字段(如字符数组引用)设置为指向常量池中该字面量对应的字符串对象的内部字段。但新创建的字符串对象和常量池中的字符串对象是两个不同的对象,它们只是内部字段引用指向了相同的字符数组。
String s1 = new String(“abc”);这句话创建了几个字符串对象?
会创建 1 或 2 个字符串对象。
如果字符串常量池中不存在 “abc”,则会创建一个新的字符串对象并放入池中。
且不管常量池中是否存在“abc”字面量,new`关键字仍然会在堆上创建一个新的字符串对象。
String s1 = “abc” String s2 = new String(“abc”) 的区别
String s1 = “abc” , 如果常量池中没有该字符串的话 ,会在字符串常量池中创建一个字符串对象 “abc”,然后将s1指向这个字符串对象, 如果常量池中已经存在 "abc",则 s1 将指向常量池中已有的 "abc" 对象。
String s2 = new String(“abc”); 这行代码会在堆内存中创建一个新的字符串对象”abc”,然后s2指向这个字符串对象。
String#intern 方法有什么作用?
intern() 会检查常量池中是否已经存在一个与当前字符串内容相同的字符串。如果存在,则返回池中该字符串的引用;如果不存在,则将该字符串添加到常量池中,并返回该字符串的引用。
1 | |